Run and prune
To run PQS you need the following:- PostgreSQL database server
- Daml Sandbox or Canton Participant Node as the source of ledger data
- Any access tokens or TLS certificates required by the above
- PQS’
scribe.jaror Docker image
Running PQS
PQS application mostly runs as a long-running process, but also includes several user-interactive commands:| Command | Description |
|---|---|
pipeline ledger postgres-document | Initiate continuous ledger data export |
datastore postgres-document schema show | Infer required database schema, display it and quit |
datastore postgres-document schema apply | Infer required database schema, apply it to data store and quit |
datastore postgres-document prune | Prune transactions to a given offset inclusively and quit |
pqs-references-configuration-options how to configure each command.
PQS pipeline is crash friendly and restarts automatically. See pqs-ledger-streaming-and-recovery for more details on how PQS recovers from a crash.
Getting help
Exploring commands and parameters is easiest via the--help (and --help-verbose) arguments: For example, if you are running a downloaded .jar file:
History slicing
As described inpqs-ledger-streaming-and-recovery you can use PQS with --pipeline-ledger-start and --pipeline-ledger-stop to ask for the slice of the history you want. There are some constraints on start and stop offsets which cause PQS to fail-fast if they are violated.
You cannot use:
- Offsets that are outside ledger history
- Pruned offsets or Genesis on pruned ledger
- Offsets that lead to a gap in datastore history
- Offsets that are before the PQS datastore history
In the above examples:
- Request represents offsets requested via
--pipeline-ledger-startand--pipeline-ledger-stoparguments - Participant Node represents the availability of unpruned ledger history in the Participant Node
- Datastore represents data in the PQS database
Pruning
Pruning ledger data from the database can help reduce storage size and improve query performance by removing old and irrelevant data. PQS provides two approaches to prune ledger data: using the PQS CLI or using theprune_archived_to_offset() SQL function (see pqs-references-sql-api).
Decide on what are the oldest offsets that you will ever need in PQS and setup periodic pruning for data at offsets older than that. Thereby ensuring that your query performance does not deteriorate over time as your PQS database continuously increases in size. In case you need all data from ledger begin consider:
- data growth rate, and
- size your database server to comfortably hold that data
Data deletion and changes
Both pruning approaches (CLI and SQL function) share the same behavior in terms of data deletion and changes:- Removes archived contracts and their associated create/archive events.
- Removes exercises and their corresponding exercise events.
- Removes transactions that no longer reference active contracts.
- All currently active contracts and their history remain intact.
- All data (transactions/events/choices/contracts) for transaction with an offset greater than the pruning target remains intact.
--prune-target or as argument to prune_archived_to_offset() SQL function is the transaction with the highest offset to be affected by the pruning operation.
If the provided offset does not have a transaction associated with it, the effective target offset becomes the oldest offset that succeeds (is greater than) the provided offset.
Constraints
Some constraints apply to pruning operations (see alsopqs-references-pqs-time-model):
- The provided target offset must be within the bounds of the contiguous history. If the target offset is outside the bounds, an error is raised.
- The pruning operation cannot coincide with the latest consistent checkpoint of the contiguous history. If so, it raises an error.
Pruning from the command line
The PQS CLI provides aprune command that allows you to prune the ledger data up to a specified offset, timestamp, or duration.
For detailed information on all available options, please run:
prune command, you need to provide a pruning target as an argument. The pruning target can be an offset, a timestamp, or a duration (ISO 86011):
prune command performs a dry run, meaning it displays the effects of the pruning operation without actually deleting any data. To execute the pruning operation, add the --prune-mode Force option:
Example with timestamp and duration
In addition to providing an offset as--prune-target, a timestamp or duration can also be used as a pruning cut-off. For example, to prune data older than 30 days (relative to now), you can use the following command:
Pruning with sql function
Theprune_archived_to_offset() is a SQL function that allows you to prune the ledger data up to a specified offset. It has the same behavior as the datastore postgres-document prune command, but does not feature a dry-run option.
To use prune_archived_to_offset(), you need to provide an offset:
prune_archived_to_offset() in combination with the nearest_offset() function to prune data up to a specific timestamp or interval:
Resetting
Reset-to-offset is a manual procedure that deletes all transactions from the PQS database after a given offset. This allows you to restart processing from the offset as if subsequent transactions have never been processed. Reset can be useful to perform a point-in-time rollback of the ledger in a range of circumstances. For example, in the event of:- Unexepected new entities - A new scope, such as a Party or template, appears in ledger transactions without coordination. That is, new transactions arrive without ensuring PQS is restarted - to ensure it knows about these new enitities prior.
- Ledger roll-back - If a ledger is rolled-back due to the disaster recovery process, you will need to perform a similar roll back with PQS. This is a manual process that requires coordination with the Participant Node.
- Stop any applications that use the PQS database.
- Stop the PQS process.
- Connect to the PostgreSQL as an administrator.
-
Prevent PQS database readers from interacting (
revoke connect). -
Terminate any other remaining connections:
-
Obtain a summary of the scope of the proposed reset and validate that the intended outcome matches your expectations by performing a dry run:
-
Implement the destructive changes of removing all transactions after the given offset and adjust internal metadata to allow PQS to resume processing from the supplied offset:
-
Re-enable access for PQS database users (
grant connect) - Wait for the Participant Node to be available post-repair.
- Start PQS.
- Conduct any remedial action required in PQS database consumers, to account for the fact that the ledger appears to be rolled back to the specified offset.
- Start applications that use the PQS database and resume operation.
If the database was previously pruned and the reset target offset is below the stored pruning offset,
reset_to_offset retreats the pruning offset to the reset target. After such a reset, pruned_offset() returns the new target offset. If the reset target is at or above the pruning offset, the pruning state is preserved.Redacting
The redaction feature enables removal of sensitive or personally identifiable information from contracts and exercises within the PQS database. This operation is particularly useful for complying with privacy regulations and data protection laws, as it enables the permanent removal of contract payloads, contract keys, choice arguments, and choice results. Note that redaction is a destructive operation and once redacted, information cannot be restored. The redaction process involves assigning aredaction_id to a contract or an exercise and nullifying its sensitive data fields. For contracts, the payload and contract_key fields are redacted, while for exercises, the argument and result fields are redacted.
Conditions for redaction
The following conditions apply to contracts and interface views:- You cannot redact an active contract
- A redacted contract cannot be redacted again
Examples
Redacting an archived contract
To redact an archived contract, use theredact_contract function by providing the contract_id and a redaction_id. The intent of the redaction_id is to provide a case reference to identify the reason why the redaction has taken place, and it should be set according to organizational policies. This operation nullifies the payload and contract_key of the contract and assigns the redaction_id.
Redacting a choice exercise
To redact an exercise, use theredact_exercise function by providing the event_id of the exercise and a redaction_id. This nullifies the argument and result of the exercise and assigns the redaction_id.
Accessing redaction information
Theredaction_id of a contract is exposed as a column in the following functions of the SQL API. The columns payload and contract_key for a redacted contract are NULL.
creates(...)archives(...)active(...)lookup_contract(...)
redaction_id of an exercise event is exposed as a column in the following functions of the SQL API. The columns argument and result for a redacted exercise are NULL:
exercises(...)lookup_exercises(...)
Representative package ID support
PQS does not support ingesting contract payloads where the original package ID of a Ledger API create event is not available in the Participant Node’s package store that the PQS instance is connected to. Such a situation can occur on an ACS import procedure on the Participant Node, where the original package ID is replaced by its representative package IDIf you are using ACS import/export procedures that can replace the original package ID of contracts, please ensure that the original package IDs are also uploaded to the Participant Node’s package store to avoid disruptions in PQS processing.
Observe
This section describes observability features of PQS, which are designed to help you monitor health and performance of the application.Approach to observability
PQS opted to incorporate OpenTelemetry APIs to provide its observability features. All three sources of signals (traces, metrics, and logs) can be exported to various backends by providing appropriate configuration defined by OpenTelemetry protocols and guidelines. This makes PQS flexible in terms of observability backends, allowing users to choose what fits their needs and established infrastructure without being overly prescriptive. To have PQS emit observability data, an OpenTelemetry Java Agent must be attached to the JVM running PQS. OpenTelemetry’s documentation page on Java Agent Configuration1 has all the necessary information to get started. As a frequently requested shortcut (only metrics over Prometheus exposition endpoint embedded by PQS), the following snippet can help you get started. For more details, refer to the official documentation:Logging
Log level
Set log level with--logger-level. Possible value are All, Fatal, Error, Warning, Info (default), Debug, Trace:
Per-logger log level
Use--logger-mappings to adjust the log level for individual loggers. For example, to remove Netty network traffic from a more detailed overall log:
Log pattern
With--logger-pattern, use one of the predefined patterns, such as Plain (default), Standard (standard format used in DA applications), Structured, or set your own. Check Log Format Configuration2 for more details.
To use your custom format, provide its string representation, such as:
Log format for console output
Use--logger-format to set the log format. Possible values are Plain (default) or Json. These formats can be used for the pipeline command.
Log format for file output
Use--logger-format to set the log format. Possible values are Plain (default), Json, PlainAsync and JsonAsync. They can be used for the interactive commands, such as prune. For PlainAsync and JsonAsync, log entries are written to the destination file asynchronously.
Destination file for file output
Use--logger-destination to set the path to the destination file (default: output.log) for interactive commands, such as prune.
Log format and log pattern combinations
-
Plain/Plain -
Plain/Standard -
Plain/Custom -
Json/Standard -
Json/Structured -
Json/CustomNotice you need to use%label{your_label}{format}to describe a Json attribute-value pair.
Application metrics
Assuming PQS exposes metrics as described above, you can access the following metrics athttp://localhost:9090/metrics. Each metric is accompanied by # HELP and # TYPE comments, which describe the meaning of the metric and its type, respectively.
Some metric types have additional constituent parts exposed as separate metrics. For example, a histogram metric type tracks max, count, sum, and actual ranged buckets as separate time series. Metrics are labeled where it makes sense, providing additional context such as the type of operation or the template/choice involved.
Conceptual list of metrics (refer to actual metric names in the Prometheus output):
| Type | Name | Description |
|---|---|---|
| gauge | watermark_ix | Current watermark index (transaction ordinal number for consistent reads) |
| counter | pipeline_events_total | Processed ledger events |
| histogram | jdbc_conn_use | Latency of database connections usage |
| histogram | jdbc_conn_isvalid | Latency of database connection validation |
| histogram | jdbc_conn_commit | Latency of database connection commit |
| histogram | total_tx_handling_latency | Total latency of transaction handling in PQS (observed in LAPI to committed in DB) |
| gauge | tx_lag_from_ledger_wallclock | Lag from ledger (wall-clock delta (in ms) from command completion to receipt by pipeline) |
| histogram | pipeline_convert_acs_event | Latency of converting ACS events |
| histogram | pipeline_convert_transaction | Latency of converting transactions |
| histogram | pipeline_prepare_batch_latency | Latency of preparing batches of statements |
| histogram | pipeline_execute_batch_latency | Latency of executing batches of statements |
| histogram | pipeline_progress_watermark_latency | Latency of watermark progression |
| histogram | pipeline_wp_acs_events_size | Number of in-flight units of work in pipeline_wp_acs_events wait point |
| histogram | pipeline_wp_acs_statements_size | Number of in-flight units of work in pipeline_wp_acs_statements wait point |
| histogram | pipeline_wp_acs_batched_statements_size | Number of in-flight units of work in pipeline_wp_acs_batched_statements wait point |
| histogram | pipeline_wp_acs_prepared_statements_size | Number of in-flight units of work in pipeline_wp_acs_prepared_statements wait point |
| histogram | pipeline_wp_events_size | Number of in-flight units of work in pipeline_wp_events wait point |
| histogram | pipeline_wp_statements_size | Number of in-flight units of work in pipeline_wp_statements wait point |
| histogram | pipeline_wp_batched_statements_size | Number of in-flight units of work in pipeline_wp_batched_statements wait point |
| histogram | pipeline_wp_prepared_statements_size | Number of in-flight units of work in pipeline_wp_prepared_statements wait point |
| histogram | pipeline_wp_watermarks_size | Number of in-flight units of work in pipeline_wp_watermarks wait point |
| counter | pipeline_wp_acs_events_total | Number of units of work processed in pipeline_wp_acs_events wait point |
| counter | pipeline_wp_acs_statements_total | Number of units of work processed in pipeline_wp_acs_statements wait point |
| counter | pipeline_wp_acs_batched_statements_total | Number of units of work processed in pipeline_wp_acs_batched_statements wait point |
| counter | pipeline_wp_acs_prepared_statements_total | Number of units of work processed in pipeline_wp_acs_prepared_statements wait point |
| counter | pipeline_wp_events_total | Number of units of work processed in pipeline_wp_events wait point |
| counter | pipeline_wp_statements_total | Number of units of work processed in pipeline_wp_statements wait point |
| counter | pipeline_wp_batched_statements_total | Number of units of work processed in pipeline_wp_batched_statements wait point |
| counter | pipeline_wp_prepared_statements_total | Number of units of work processed in pipeline_wp_prepared_statements wait point |
| counter | pipeline_wp_watermarks_total | Number of units of work processed in pipeline_wp_watermarks wait point |
| counter | app_restarts_total | Tracks number of times recoverable failures forced the pipeline to restart |
| gauge | grpc_up | Indicator whether gRPC channel is up and operational |
| gauge | jdbc_conn_pool_up | Indicator whether JDBC connection pool is up and operational |
Grafana dashboard
Based on the metrics described above, it is possible to build a comprehensive dashboard to monitor PQS. Vendor-supplied Grafana dashboard for PQS can be downloaded from artifacts repository (seepqs-download). You may want to refer to this as a starting point for your own.
Health check
The health of the PQS process can be monitored using the health check endpoint/livez. The health check endpoint is available on the configured network interface (--health-address) and TCP port (--health-port). Note the default is 127.0.0.1:8080.
Tracing of pipeline execution
PQS instruments the most critical parts of its operations with tracing to provide insights into the execution flow and performance. Traces can be exported to various OpenTelemetry backends by providing appropriate configuration, for example:| span name | description |
|---|---|
process metadata and schema | interactions that happen when PQS starts up and ensures its datastore is ready for operations |
initialization routine | interactions that happen when PQS establishes its offset range boundaries (including seeding from ACS if requested) on startup |
consume com.daml.ledger.api.v1.TransactionService/GetTransactions consume com.daml.ledger.api.v1.TransactionService/GetTransactionTrees | [Daml SDK v2.x] timeline of processing a ledger transaction from delivery over gRPC to its persistence to datastore |
consume com.daml.ledger.api.v2.UpdateService/GetUpdates consume com.daml.ledger.api.v2.UpdateService/GetUpdateTrees | [Daml SDK v3.x] timeline of processing a ledger transaction from delivery over gRPC to its persistence to datastore |
execute datastore transaction | interactions when a batch of transactions is persisted to the datastore |
advance datastore watermark | interactions when the latest consecutive watermark is persisted to the datastore |
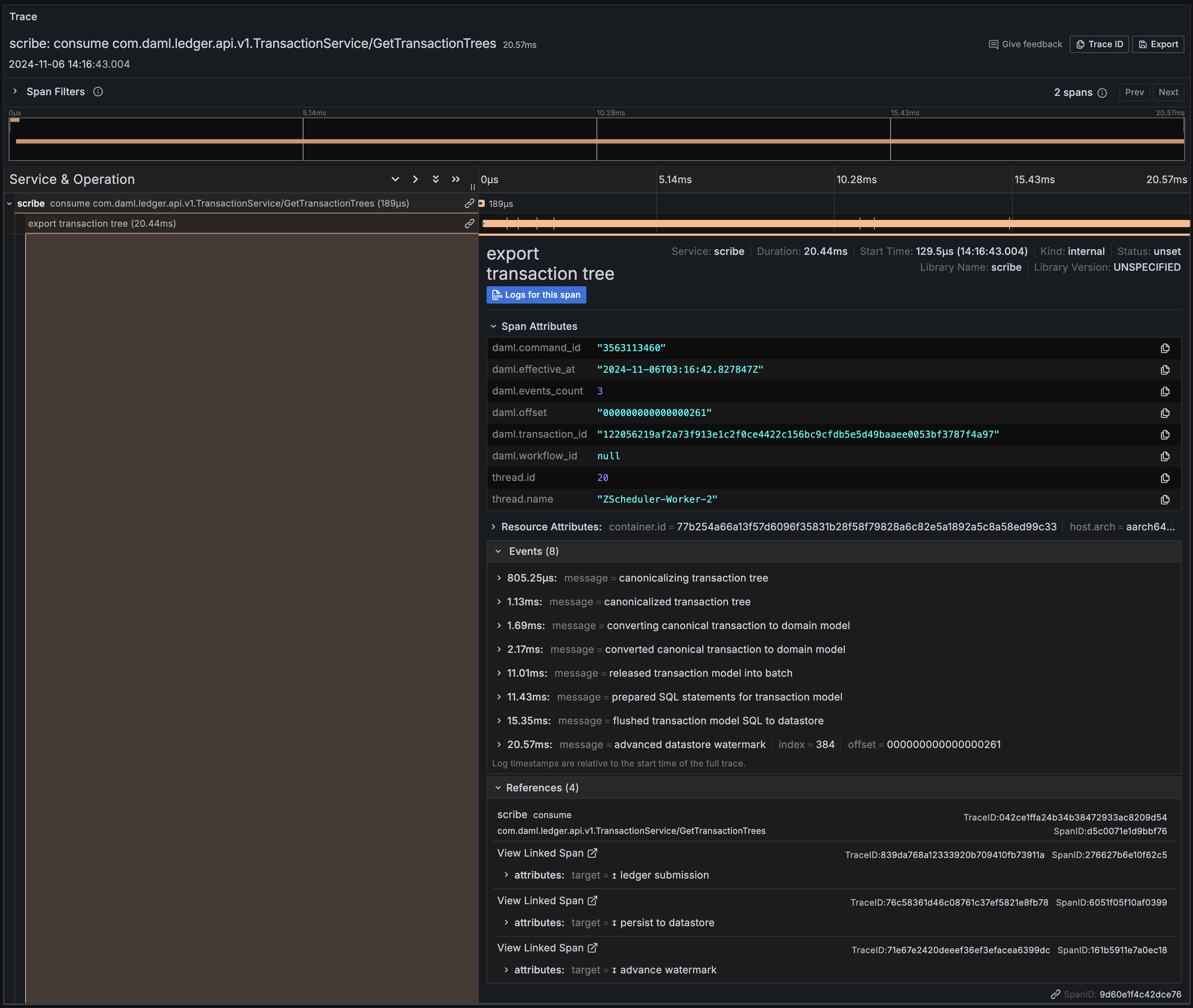
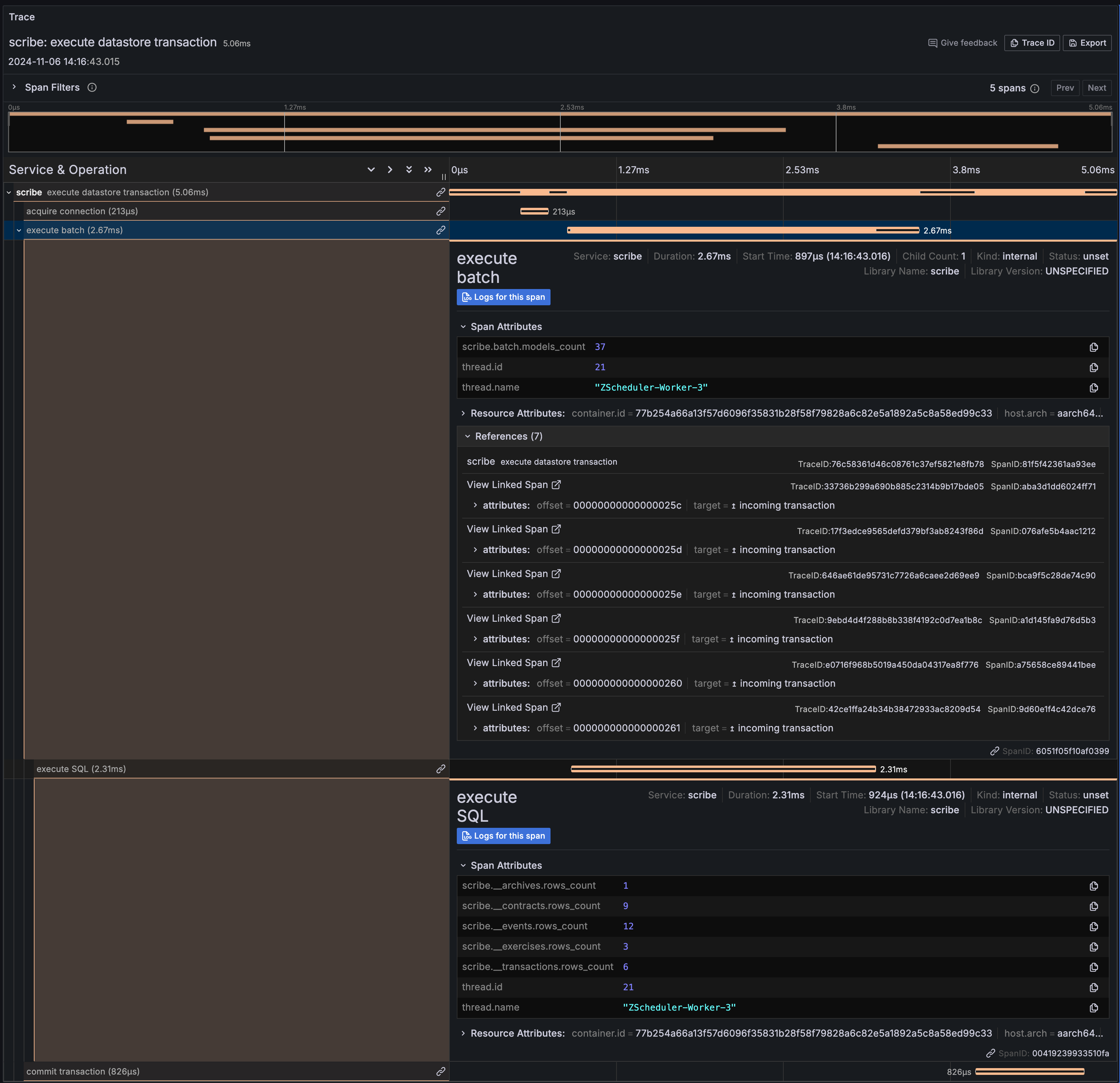
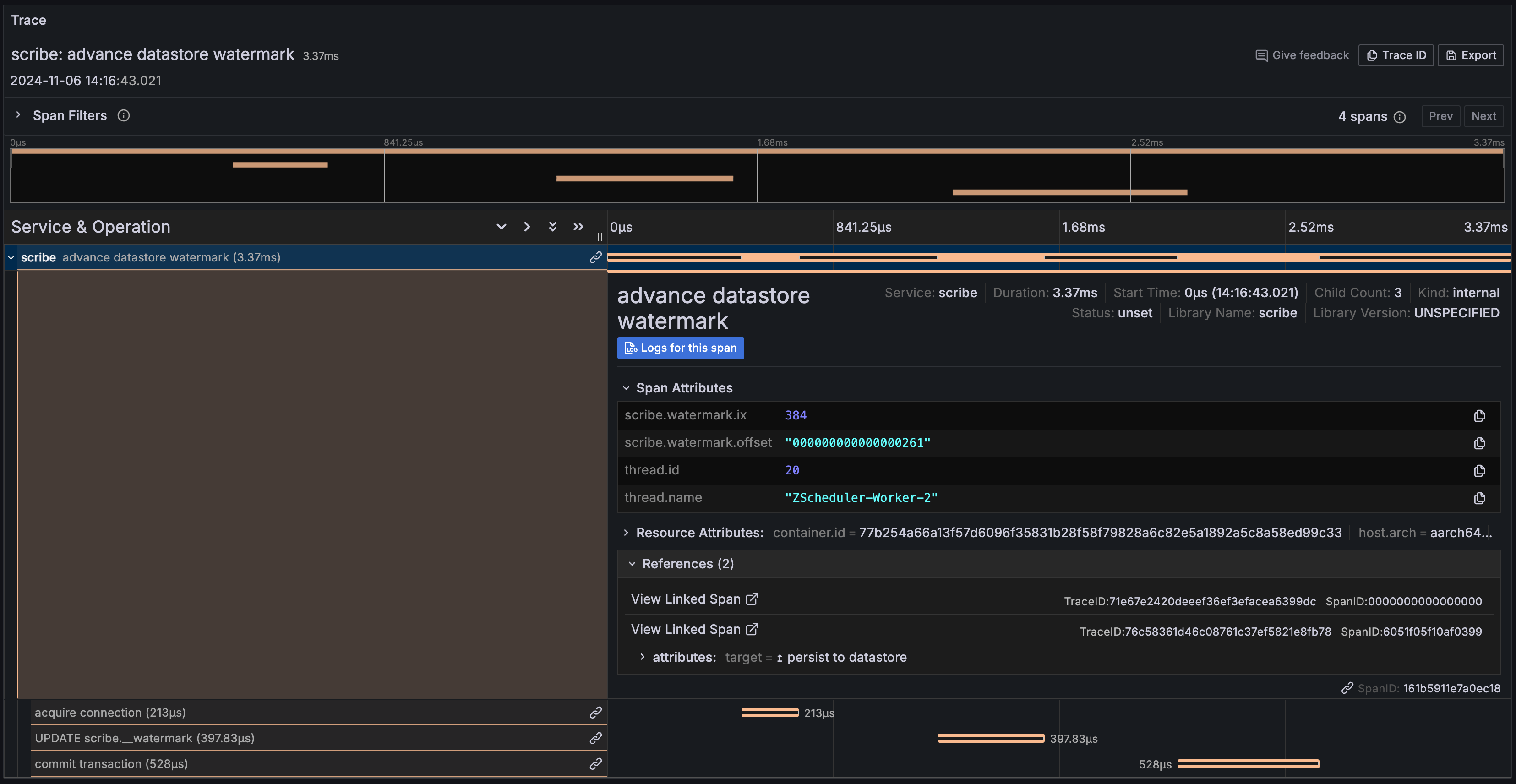
Trace context propagation
PQS is an intermediary between a ledger instance and downstream applications that would prefer to access data through SQL rather than in streaming manner from Ledger API directly. Despite forming a pipeline between two data storage systems (Canton and PostgreSQL), PQS stores the original ledger transaction’s trace context (see alsoopen-tracing-ledger-api-client) for the purposes of propagation rather than its own. This allows downstream applications to decide for themselves how they want to connect to the original submission’s trace (as a child span or as a new trace connected through span links).
transactions.trace_context column allows any application to re-create the propagated trace context4 and use it with their runtime’s instrumentation library.
Diagnostics
PQS is capable of exporting diagnostic telemetry snapshots. This data export archive contains essential troubleshooting information such as:- application thread dumps (over a period of time)
- application metrics (over a period of time)
netcat tool:
| System property | Environment variable | Default value | Description |
|---|---|---|---|
da.diagnostics.enabled | DA_DIAGNOSTICS_ENABLED | true | Enables/disables diagnostics data collection and exposition |
da.diagnostics.host | DA_DIAGNOSTICS_HOST | 127.0.0.1 | Hostname or IP address to use for binding the exposition socket |
da.diagnostics.port | DA_DIAGNOSTICS_PORT | 0 | Port to use for binding the exposition socket (0 = random port) |
da.diagnostics.dump.path | DA_DIAGNOSTICS_DUMP_PATH | <empty> | Directory to write to on graceful shutdown (path needs to be an existing writable directory) |
da.diagnostics.metrics.interval | DA_DIAGNOSTICS_METRICS_INTERVAL | PT10S | Metrics collection interval in ISO 8601 format |
da.diagnostics.metrics.buffer.size | DA_DIAGNOSTICS_METRICS_BUFFER_SIZE | 60 | Quantity of samples to store for each monitored metric (rolling window) |
da.diagnostics.metrics.tags | DA_DIAGNOSTICS_METRICS_TAGS | <empty> | Comma-separated list of additional labels to enrich each metric with during exposition (for example, job=myapp,env=staging,deployed=20250101) |
da.diagnostics.threads.interval | DA_DIAGNOSTICS_THREADS_INTERVAL | PT1M | Thread dumps collection interval in ISO 8601 format |
da.diagnostics.threads.buffer.size | DA_DIAGNOSTICS_THREADS_BUFFER_SIZE | 10 | Quantity of thread dumps to store (rolling window) |
Recover
PQS is designed to operate as a long-running process which uses these principles to enhance availability:- Redundancy involves running multiple instances of PQS in parallel to ensure that the system remains available even if one instance fails.
- Retry involves healing from transient and recoverable failures without shutting down the process or requiring operator intervention.
- Recovery entails reconciling the current state of the ledger with already exported data in the datastore after a cold start, and continuing from the latest checkpoint.
High availability
Multiple isolated instances of PQS can be instantiated without any cross-dependency. This allows for an active-active high availability clustering model. Please note that different instances might not be at the same offset due to different processing rates and general network non-determinism. PQS’ SQL API provides capabilities to deal with this ‘eventual consistency’ model, to ensure that readers have at least ‘repeatable read’ consistency. Seevalidate_offset_exists() in pqs-references-offset-management for more details.
Retries
PQS’pipeline command is a unidirectional streaming process that heavily relies on the availability of its source and target dependencies. When PQS encounters an error, it attempts to recover by restarting its internal engine, if the error is designated as recoverable:
- gRPC1 (white-listed; retries if):
CANCELLEDDEADLINE_EXCEEDEDNOT_FOUNDPERMISSION_DENIEDRESOURCE_EXHAUSTEDFAILED_PRECONDITIONABORTEDINTERNALUNAVAILABLEDATA_LOSSUNAUTHENTICATED
- JDBC2 (black-listed; retries unless):
INVALID_PARAMETER_TYPEPROTOCOL_VIOLATIONNOT_IMPLEMENTEDINVALID_PARAMETER_VALUESYNTAX_ERRORUNDEFINED_COLUMNUNDEFINED_OBJECTUNDEFINED_TABLEUNDEFINED_FUNCTIONNUMERIC_CONSTANT_OUT_OF_RANGENUMERIC_VALUE_OUT_OF_RANGEDATA_TYPE_MISMATCHINVALID_NAMECANNOT_COERCEUNEXPECTED_ERROR
- Daml packages (retries if):
- A transaction references a Daml package that was not present when the pipeline started.
Configuration
The followingpqs-references-configuration-options are available to control the retry behavior of PQS:
--retry-backoff-* settings control periodicity of retries and the maximum duration between attempts.
Configuring --retry-counter-attempts and --retry-counter-duration controls the maximum instability tolerance before shutting down.
Configuring --retry-counter-reset controls the period of stability after which the retry counters are reset across the board.
Dynamic Daml package reload
When PQS encounters a transaction referencing an unknown Daml package, it does not terminate. Instead:- Ingestion pauses.
- PQS fetches new packages from the Participant Node.
- Type mappings are rebuilt.
- Ingestion resumes from the paused offset.
app_restarts_total with label exception="Recoverable: unknown Daml package detected." increments each time this occurs.
Dynamic package reload only applies to newly deployed Daml packages. Other configuration changes (parties, templates, interfaces in filters) still require a restart.
Logging
While PQS recovers, the following log messages are emitted to indicate the progress of the recovery:Metrics
The following metrics are available to monitor stability of PQS’ dependencies. Seepqs-application-metrics for more details on general observability:
Retry counters reset
If PQS encounters network unavailability it starts incrementing retry counters with each attempt. These counters are reset only after a period of stability, as defined by--retry-counter-reset. As such, during the prolonged periods of intermittent failures that alternate with brief periods of operating normally, PQS keeps maintaining a cautious stance on assumptions regarding the stability of the overall system. This can be illustrated with an example below:
As an example, for the setting --retry-counter-reset PT5M the following timeline illustrates how the retry works:
Exit codes
PQS terminates with the following exit codes:0: Normal termination1: Termination due to unrecoverable error or all retry attempts for recoverable errors have been exhausted
Ledger streaming & recovery
On (re-)start, PQS determines last saved checkpoint and continues incremental processing from that point onward. PQS is able to start and finish at prescribed ledger offsets, specified via args. In many scenarios--pipeline-ledger-start Oldest --pipeline-ledger-stop Never is the most appropriate configuration, for both initial population of all available history, and also catering for resumption/recovery processing.
Start offset meanings:
| Value | Meaning |
|---|---|
Genesis | Commence from the first offset of the ledger, failing if not available. |
Oldest | Resume processing, or start from the oldest available offset of the ledger (if the datastore is empty). |
Latest | Resume processing, or start from the latest available offset of the ledger (if the datastore is empty). |
<offset> | Offset from which to start processing, terminating if it does not match the state of the datastore. |
| Value | Meaning |
|---|---|
Latest | Process until reaching the latest available offset of the ledger, then terminate. |
Never | Keep processing and never terminate. |
<offset> | Process until reaching this offset, then terminate. |
If the ledger has been pruned beyond the offset specified in
--pipeline-ledger-start, PQS fails to start. For more details see pqs-history-slicing.Secure
PQS application is a client to backend services (ledger and database) as such it needs to respect security settings mandated by those services - TLS and authentication:TLS
Your server-side components (Canton and PostgreSQL) may require TLS to be used. Please refer to their documentation for instructions:- for PostgreSQL see https://www.postgresql.org/docs/current/ssl-tcp.html
- for Canton see
tls-configuration
Ledger authentication
To run PQS with authentication you need to turn it on via--source-ledger-auth OAuth. PQS uses OAuth 2.0 Client Credentials flow1.
clientid and clientsecret) to access the token endpoint (endpoint) of the OAuth service of your choice. Optional cafile parameter is a path to the Certification Authority certificate used to access the token endpoint. If cafile is not set, the Java TrustStore is used.
Please make sure you have configured your Participant Node to use authorization (see ledger-api-jwt-configuration) and an authorization server to accept your client credentials for grant_type=client_credentials and scope=daml_ledger_api.
Audience-based token
For Audience-Based Tokens use the--pipeline-oauth-parameters-audience parameter:
Scope-based token
For Scope-Based Tokens use the--pipeline-oauth-scope parameter:
The default value of the
--pipeline-oauth-scope parameter is daml_ledger_api. Ledger API requires daml_ledger_api in the list of scopes unless custom target scope is configured.Custom Daml claims tokens
PQS authenticates as a user defined through the User Identity Management feature of Canton. Consequently, Custom Daml Claims Access Tokens are not supported. An audience-based or scope-based token must be used instead.Static access token
Alternatively, you can configure PQS to use a static access token (meaning it is not refreshed) using the--pipeline-oauth-accesstoken parameter:
Ledger API users and Daml parties
PQS connects to a Participant Node (via Ledger API) as a user defined through the User Identity Management feature of Canton. PQS gets its user identity by providing an OAuth token of that user. After authenticating, the Participant Node has the authorization information to know what Daml Party data the user is allowed to access. By default, PQS will subscribe to data for all parties available to PQS’ authenticated user. However, this scope can be limited via the--pipeline-filter-parties filter parameter (see pqs-party-filtering).
It is important to keep in mind that a PQS database instance might contain data for multiple Daml parties. To that extent, it is of paramount significance to ensure that queries are always scoped to the relevant parties, to avoid data leaks:
Token expiry
JWT tokens2 have an expiration time. PQS has a mechanism to automatically request a new access token from the Auth Server, before the old access token expires. To set when PQS should try to request a new access token, use--pipeline-oauth-preemptexpiry (default “PT1M” - one minute), meaning: request a new access token one minute before the current access token expires. This new access token is used for any future Ledger API calls.
However, for streaming calls such as GetUpdates the access token is part of the request that initiates the streaming. Canton versions prior to 2.9 terminate the stream with error PERMISSION_DENIED as soon as the old access token expires to prevent streaming forever based on the old access token. Versions 2.9+ fail with code ABORTED and description ACCESS_TOKEN_EXPIRED and PQS streams from the offset of the last successfully processed transaction.
Forward proxy
If PQS runs in a network that requires a forward proxy to reach external OAuth endpoints (for example Azure AD or Okta), configure the proxy using CLI flags:HTTPS_PROXY environment variables, set SCRIBE_PIPELINE_OAUTH_PROXY_URL to the same value.
If PQS runs inside an Istio service mesh, the Istio sidecar intercepts outbound TCP connections. For proxy connectivity to work, either create an Istio
ServiceEntry for the proxy host, or exclude the proxy port from sidecar interception using the pod annotation traffic.sidecar.istio.io/excludeOutboundPorts.PostgreSQL authentication
To authenticate to PostgreSQL, use dedicated parameters when launching the pipeline:Hardening recommendations
Use TLS: Always use TLS to encrypt data being transmitted to/from the Participant Node and the PostgreSQL datastore. This is especially important when dealing with sensitive information. Ensure that only secure TLS versions are used (for example TLS1.2+) and that strong cipher suites are configured. Client authentication should be used to ensure that only trusted clients can connect to the Participant Node and PostgreSQL datastore, such that network level security is not overly relied upon.
Logging: Ensure that logging is configured (see pqs-logging) to avoid logging sensitive information. This includes transaction details and metadata (eg. size) that is revealed in TRACE and DEBUG levels. These log levels should be used with caution, and only in a controlled environment. In production, we recommend using INFO or WARN levels.
Ledger Authorization: Follow the principle of least privilege when granting access to the Participant Node Ledger API User that PQS uses:
- Only
canReadAsauthorization to only Party’s that it requires; OR - Only
readAsAnyPartyauthorization if PQS is used as a participant-wide service and needs access to all Party data. - No
canActAsauthorization (to submit commands). PQS has no capability to submit commands to the Canton Ledger API - No
adminaccess to the Canton Ledger API.
- Operational user: SQL Insert/Update/Delete/Copy - so PQS can maintain the datastore contents. No DDL rights should be in place - PQS does not need to change the database schema.
- Others user: No write access should be granted to any other user. Excessive reading my other clients (leading to overload) should be avoided, to ensure that PQS has sufficient resources to operate.
- Admin user: PQS will need to be able to apply schema changes to the database when deploying a new version containing database changes. This should be a separate user with the minimum required privileges to perform these operations. Also, redaction operations performed by an administrator will require Select/Update rights to the database.
- Using firewalls to restrict access to PostgreSQL database, Participant Node and auth server.
- Using firewalls to restrict access to PQS. Even though it does not listen for any client connections, there are listing TCP ports for health and diagnostic purposes. By default, health and diagnostic ports are only accessible from
localhost. Before changing this configuration, ensure that all hosts granted network level access are necessary & trusted: to mitigate the risk of exploit or exposing sensitive information.
- Keeping the operating system and all software up to date with security patches.
- Using a firewall to restrict access to the PQS process (and associated PostgreSQL datastore).
- Monitoring logs for any suspicious activity, as well as errors and warnings.
- Validate that the runtime enforces least privilege principles, and contains only intended tools. We recommend using a minimal Java runtime environment (JRE) to reduce the attack surface:
- Use a minimal JRE (not JDK), for example Amazon Corretto or Azul Zulu, to reduce the attack surface.
- Consider allowing only the
jdk.attach3 module, in your chosen JRE. This enables the running process to produce more accurate stack traces when diagnostics are extracted. - Use a security manager to restrict the infrastructure permissions of the PQS process, if possible.
- Use a containerized environment (for example Docker) to isolate the PQS process from the host system and other processes.
pqs-observe).
- PQS log is monitored for errors and warnings, to ensure these do not go unnoticed.
- PQS runtime is monitored for disk, memory and other JRE concerns such as heap, garbage collection cycle rates.
- PQS health endpoint is polled regularly to verify availability.
- PostgreSQL and Participant Node servers are similarly monitored.
pqs-pruning), and ensuring that sensitive information is redacted or deleted as required by your organization’s policies and regulations.
Software Updates: Ensure that the PQS software is kept up to date with the latest security patches and updates. This includes both the PQS software itself and any dependencies it may have.